What is a GPU?
GPU is a processor with a dedicated memory area
How do I use the GPU?
To use it, you have to
- Copy memory from CPU to GPU
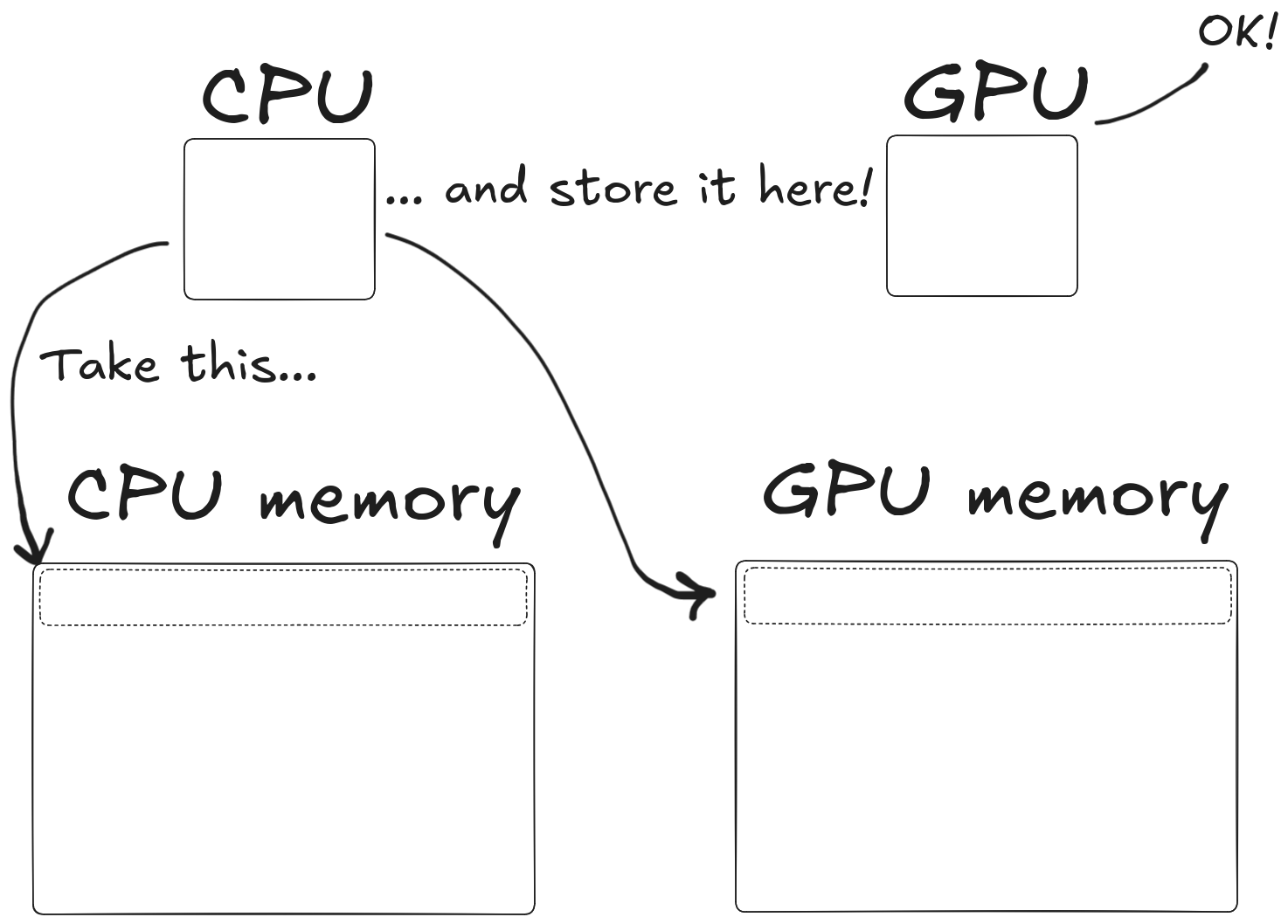
How do I use the GPU?
To use it, you have to
- Copy memory from CPU to GPU
- Tell the GPU what to do with that data
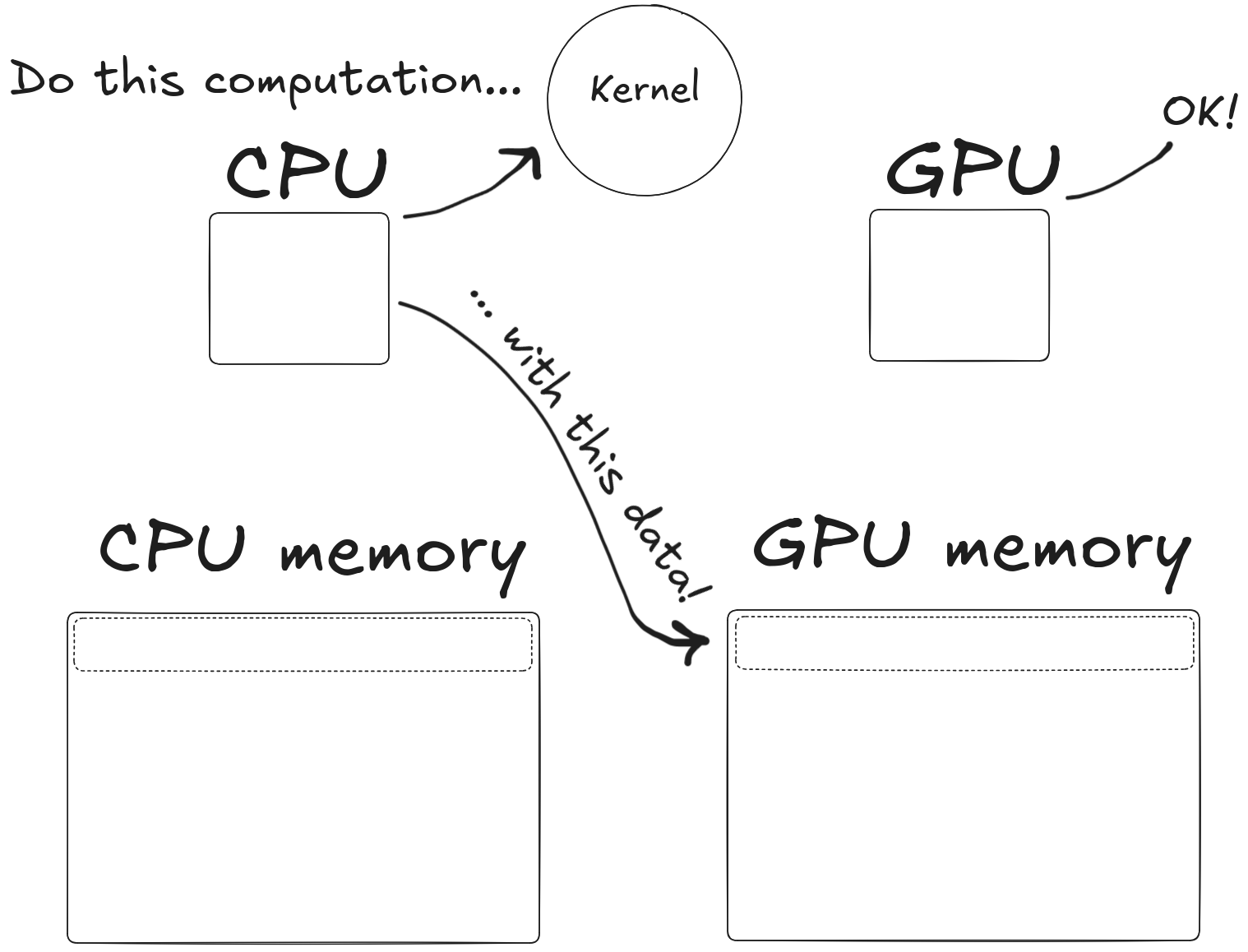
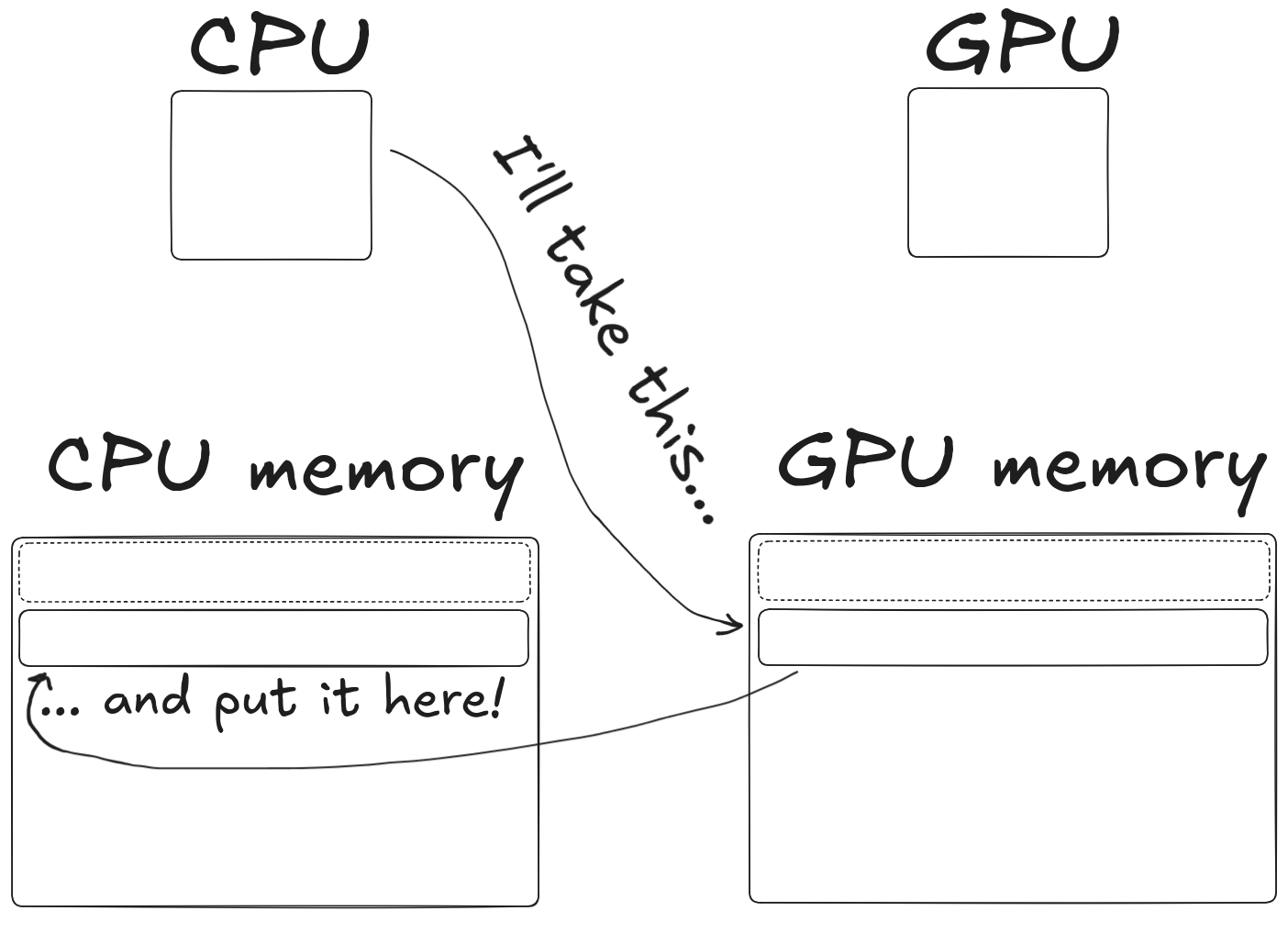
How do I use the GPU?
To use it, you have to
- Copy memory from CPU to GPU
- Tell the GPU what to do with that data
- Wait for the GPU to finish doing what you told it to do
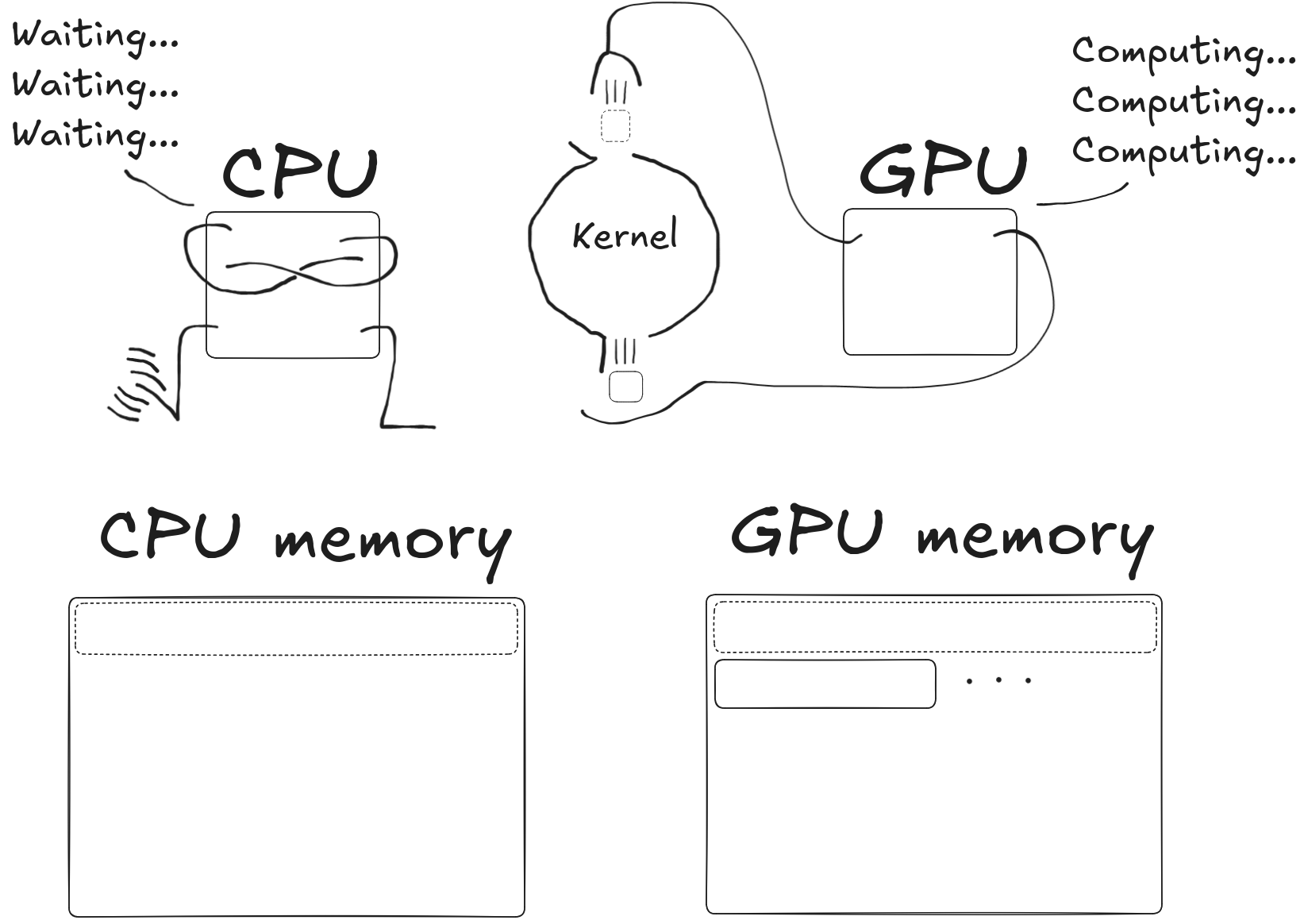
How do I use the GPU?
To use it, you have to
- Copy memory from CPU to GPU
- Tell the GPU what to do with that data
- Wait for the GPU to finish doing what you told it to do
- Copy memory from GPU back to the CPU
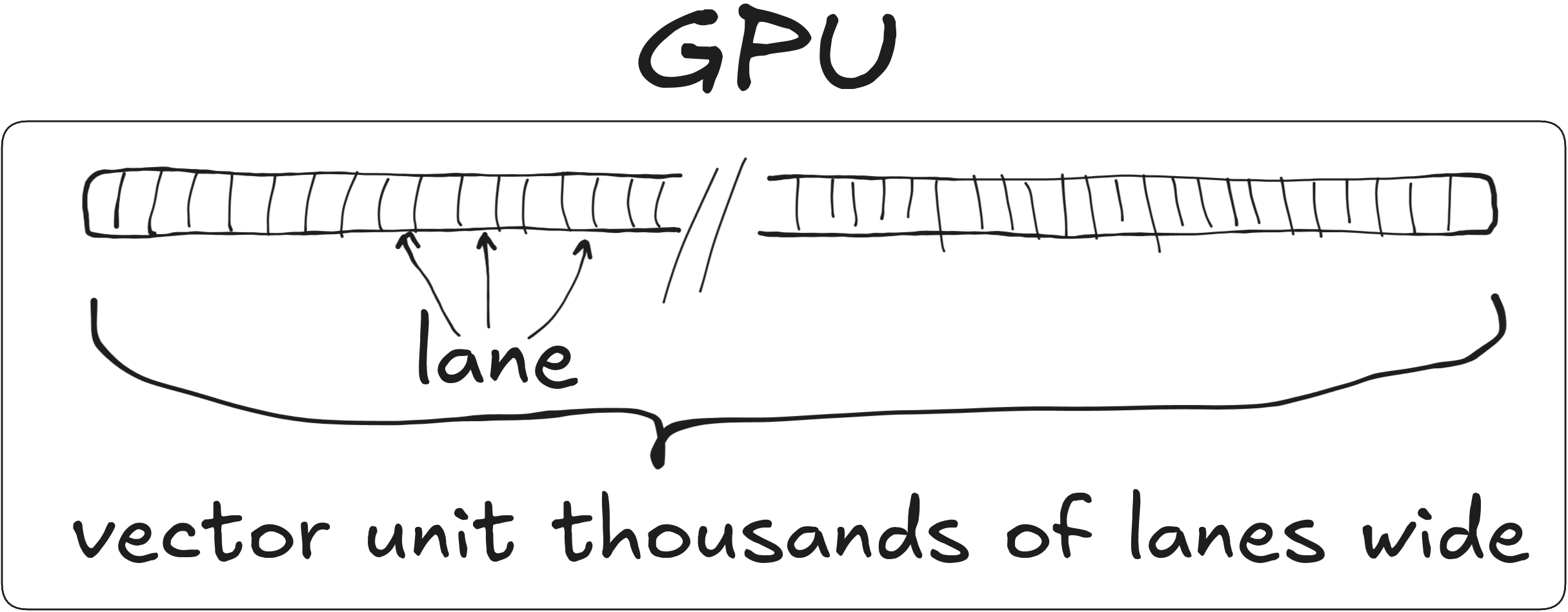
GPU as a wide SIMD unit
Scalar addition
Element-wise add for arrays a and b
resulting in array c
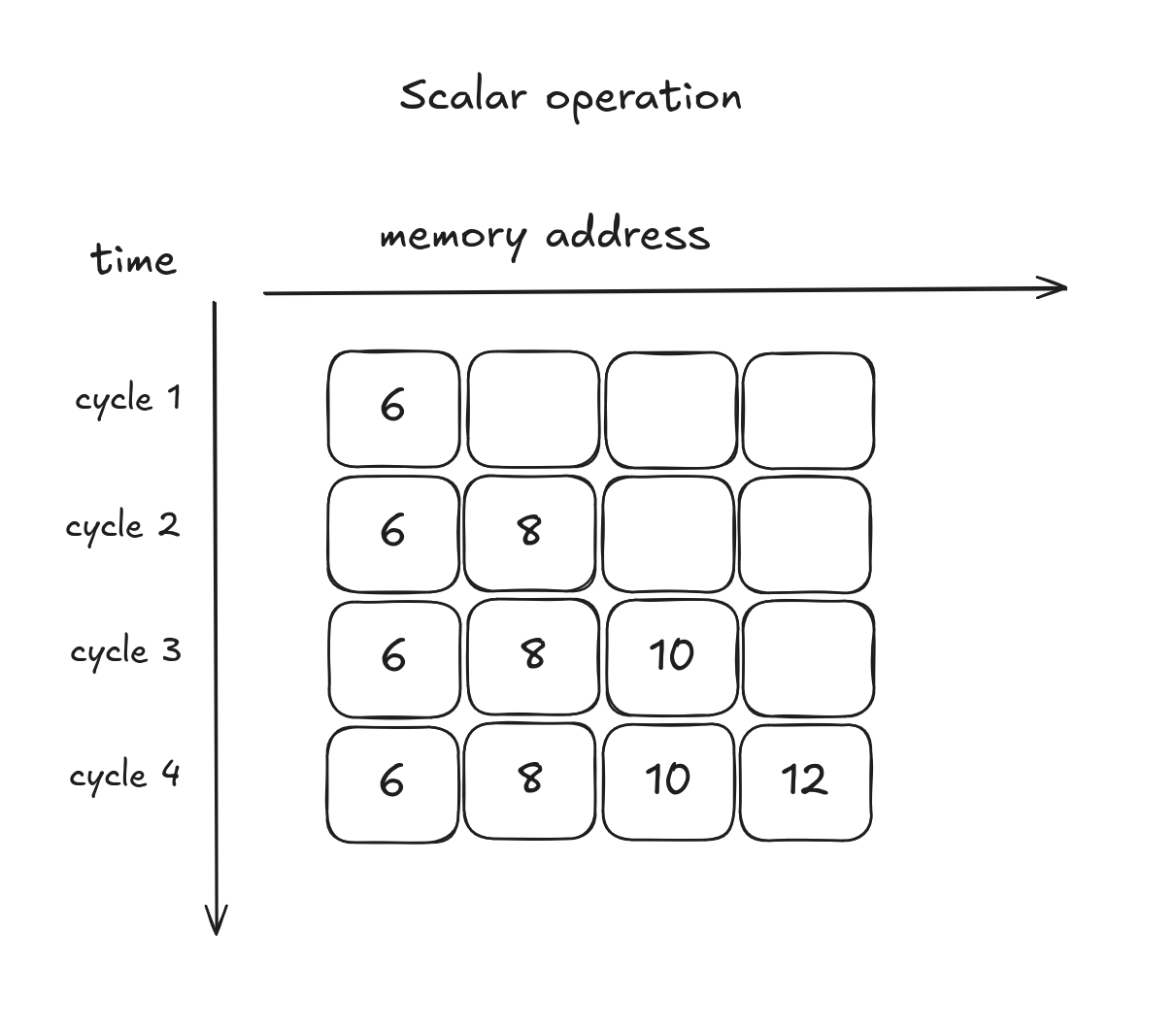
int a[4] = {1, 2, 3, 4};
int b[4] = {5, 6, 7, 8};
int c[4] = {0, 0, 0, 0};
for (int i = 0; i < 4; i++) {
c[i] = a[i] + b[i];
}
printf("{}", c); // "6, 8, 10, 12"4 cycles, 4 elements: throughput = 1
SIMD addition
Element-wise add for arrays a and b
resulting in array c
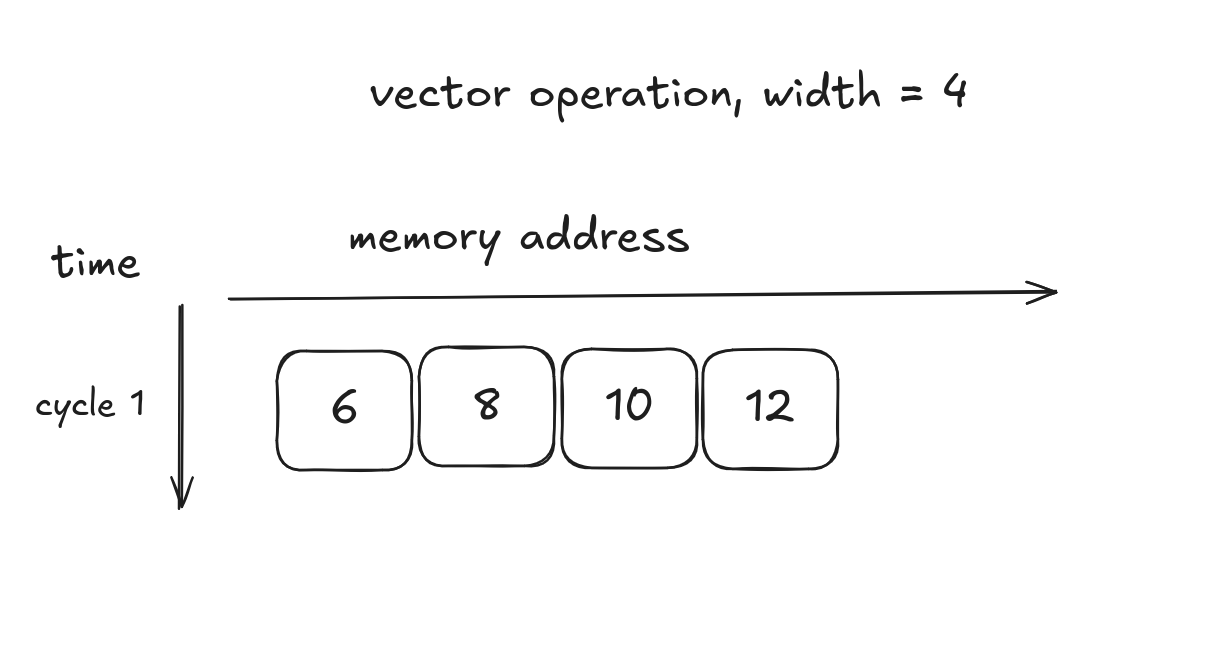
int a[4] = {1, 2, 3, 4};
int b[4] = {5, 6, 7, 8};
int c[4] = {0, 0, 0, 0};
simd_add(a, b, c);
printf("{}", c); // "6, 8, 10, 12"1 cycle, 4 elements: throughput = 4
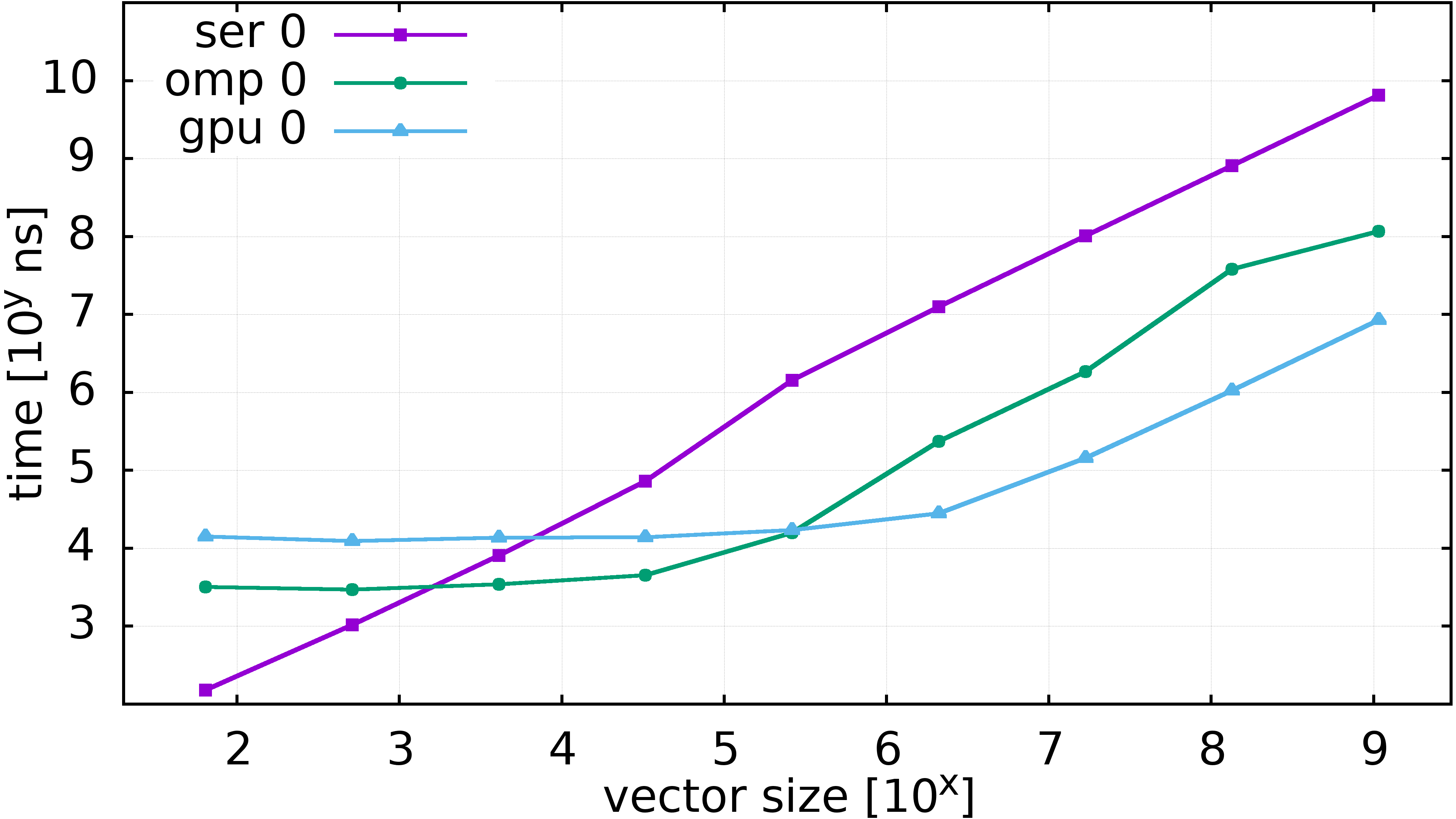
Runtimes of Taylor expansion, little computation
- \(y_i \gets \sum_{n = 0}^{0} \frac{x_i^n}{n!}\)
- \(i = 1\dots\) vector size
- Only 1 term (“\(x^0\)”) but do the arithmetic
- Init \((x_1,\dots)\) on device (GPU)
- Starting always on CPU memory would make CPU faster!
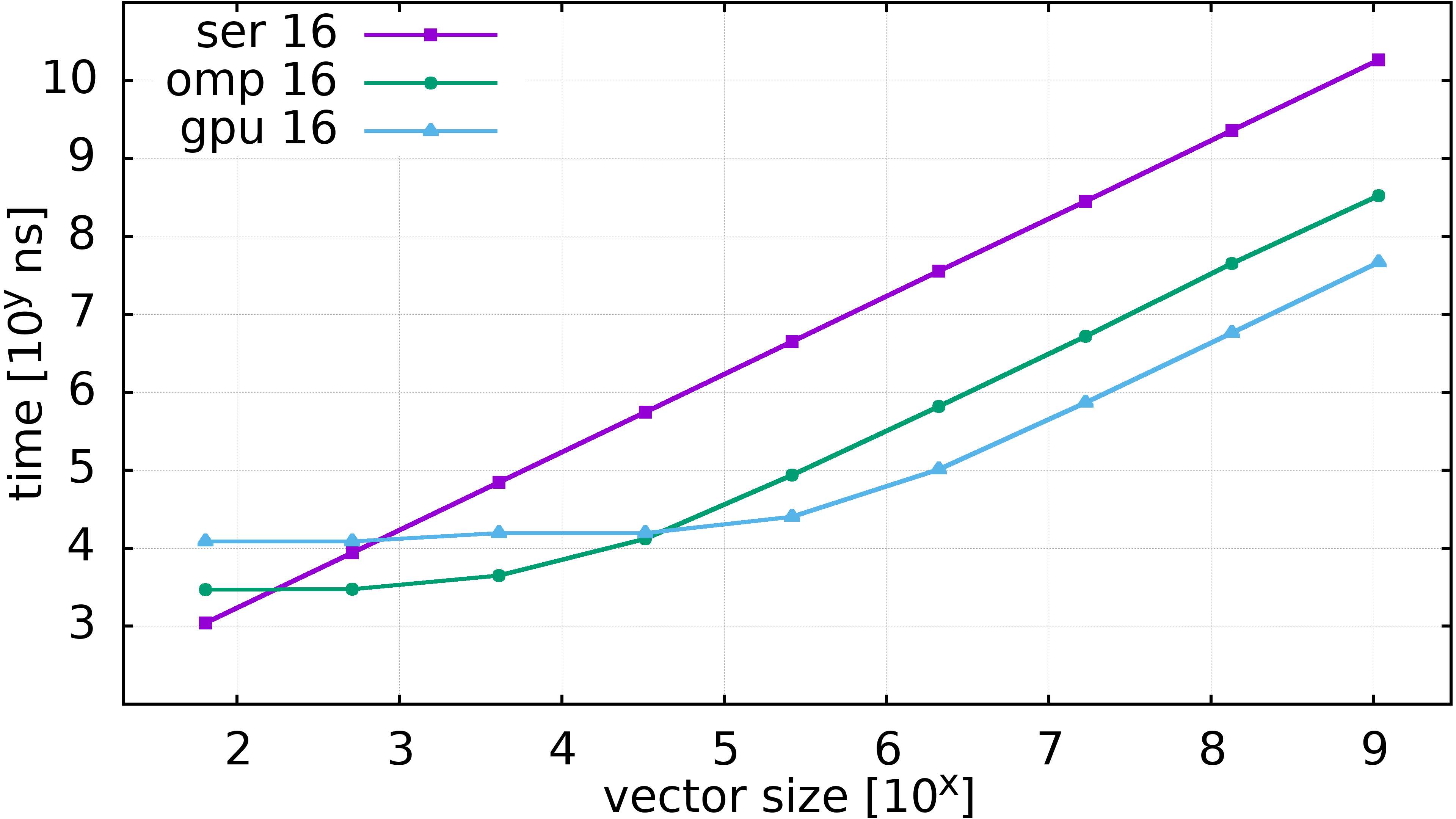
Runtimes of Taylor expansion, more computation
- \(y_i \gets \sum_{n = 0}^{16} \frac{x_i^n}{n!}\)
- Compute units are not mostly waiting for data
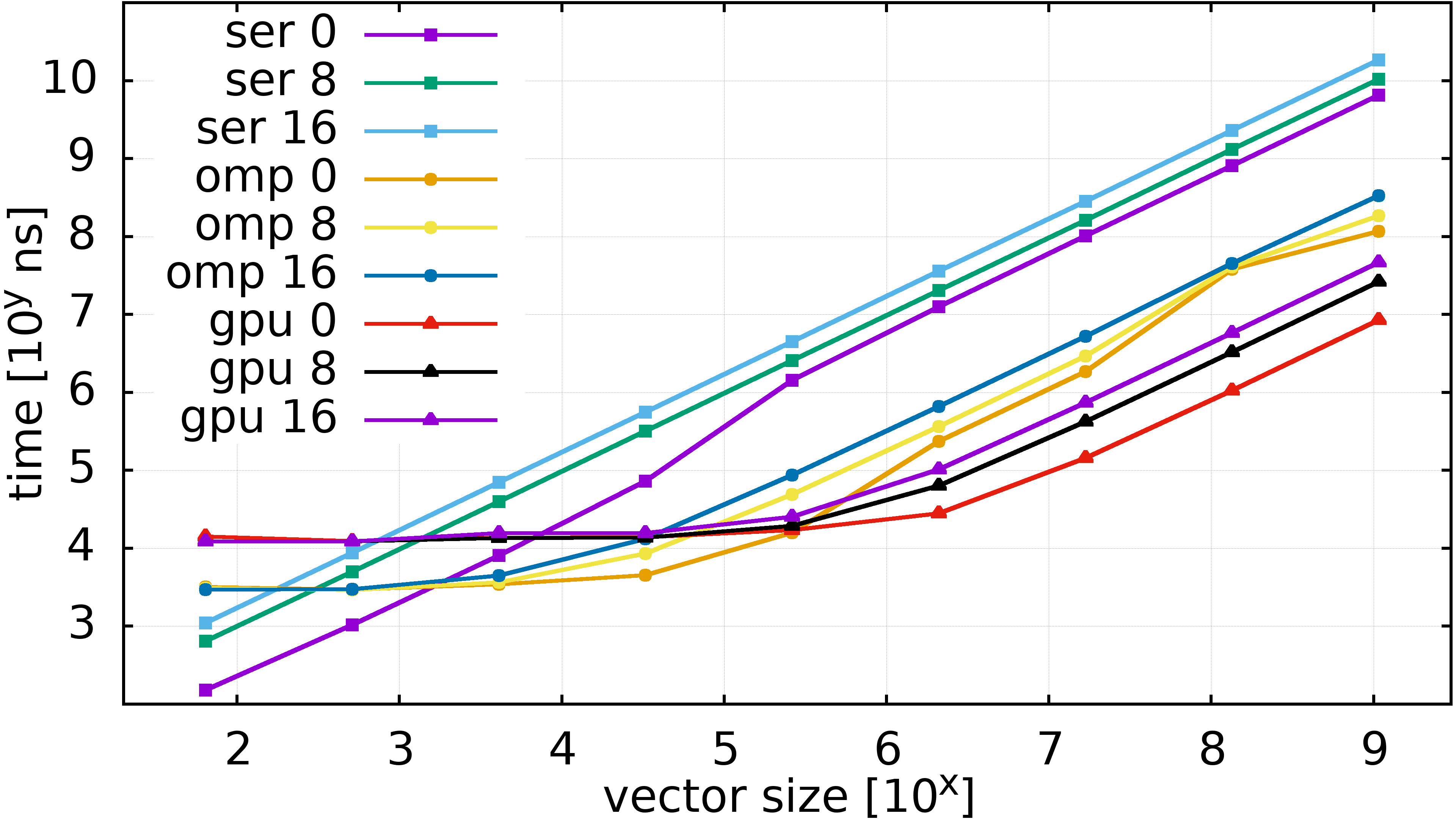
Runtimes of Taylor expansion, \(N=0,8,16\)
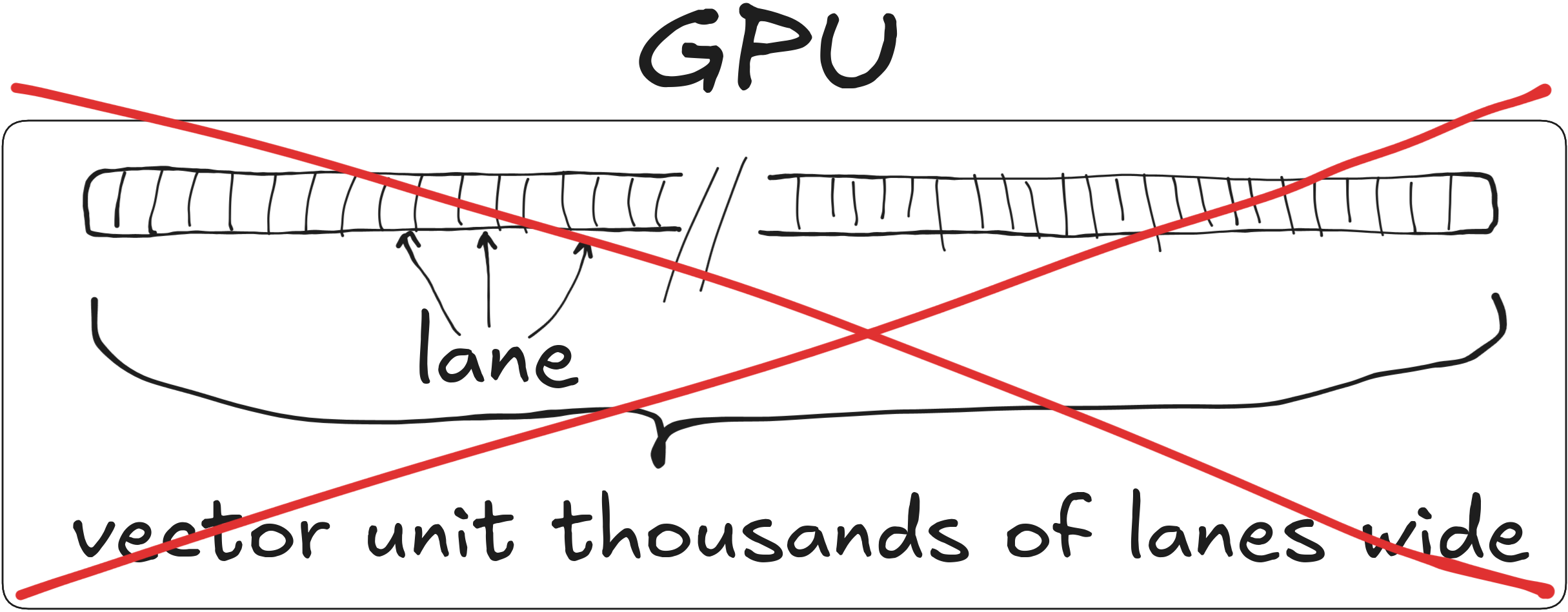
GPU as a wide SIMD unit
32 operations
1024 lanes
Utilization: \[ 32 / 1024 = 1 / 32 \approx 3\% \]
GPU as a collection of independents vector units

32 vector units
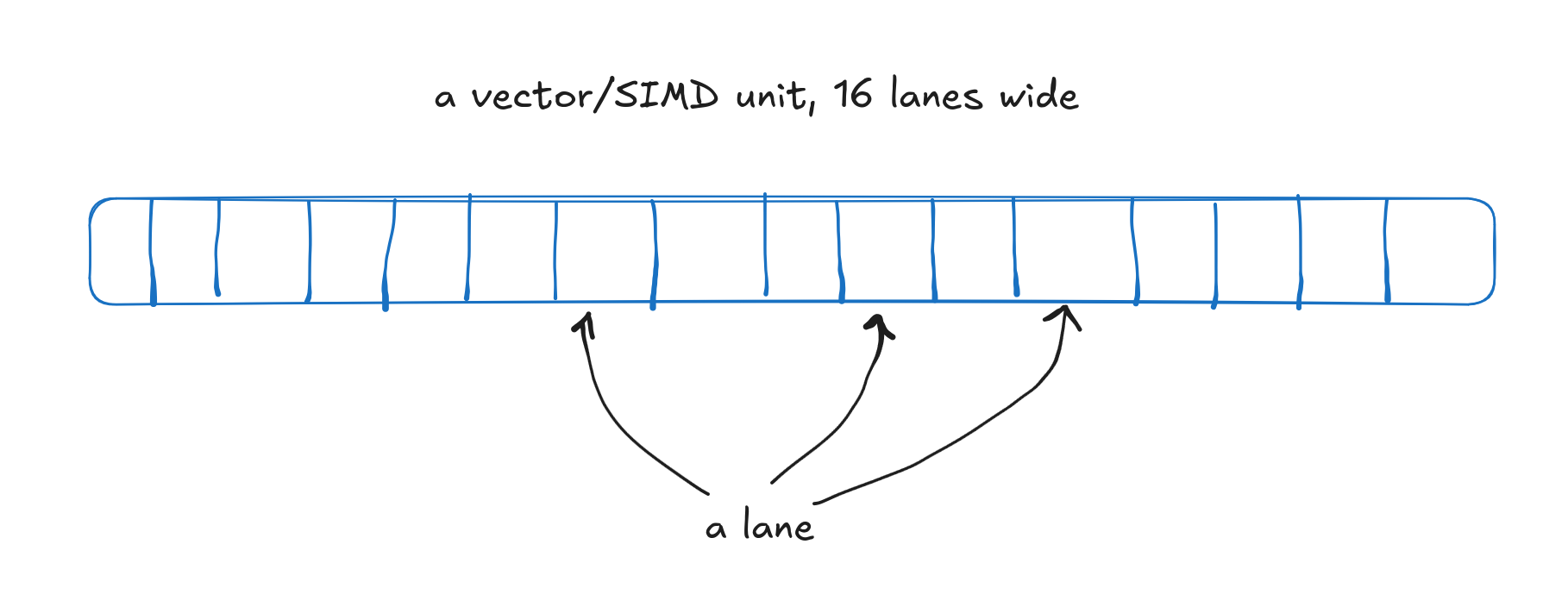
A vector unit, 16 lanes wide
GPU as a collection of independents vector units
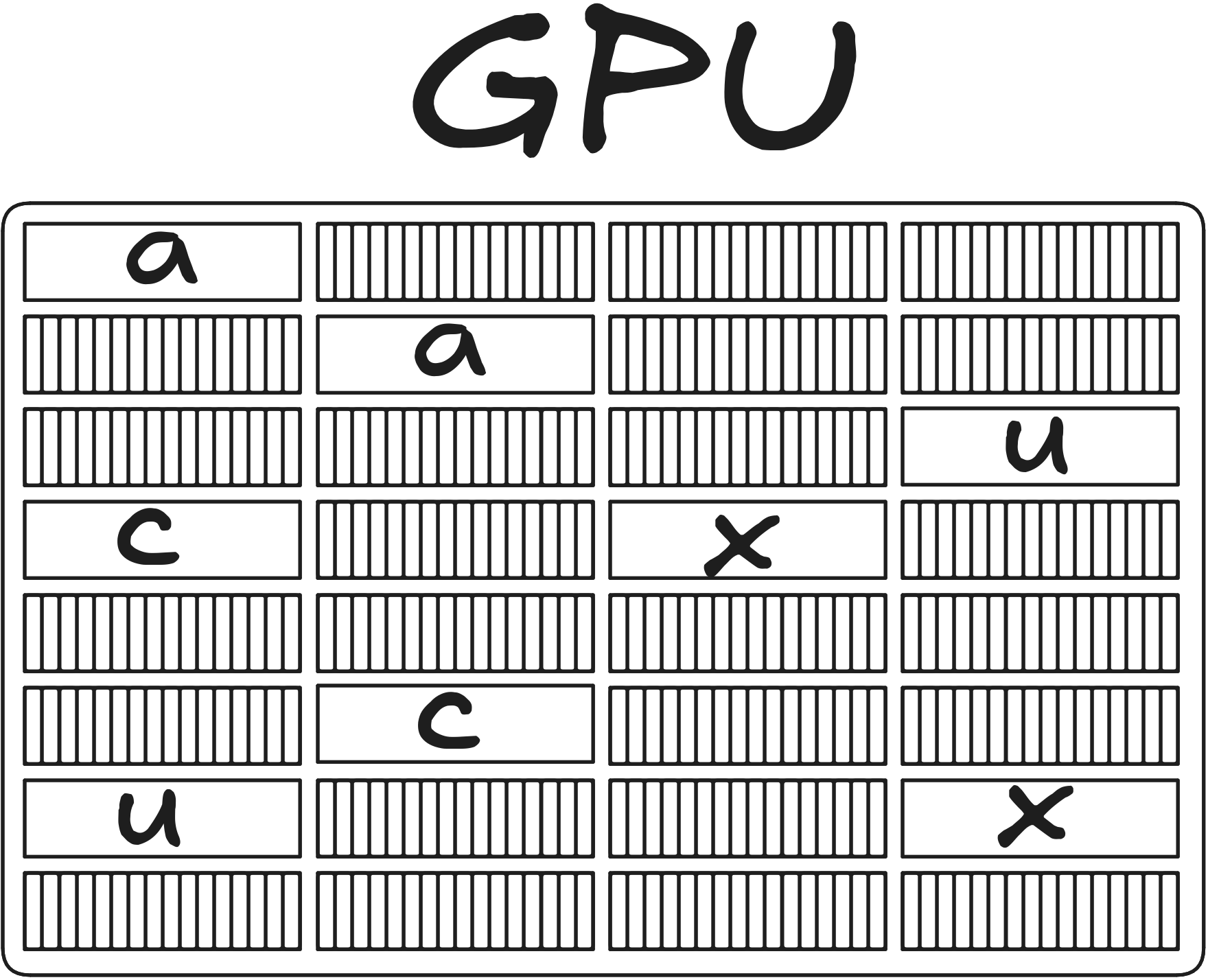
32 vector units, executing different instructions
A vector unit, 16 lanes wide
Who controls the vector units?
Is this realistic?
Who controls the vector units?

No
GPU as a collection of processors
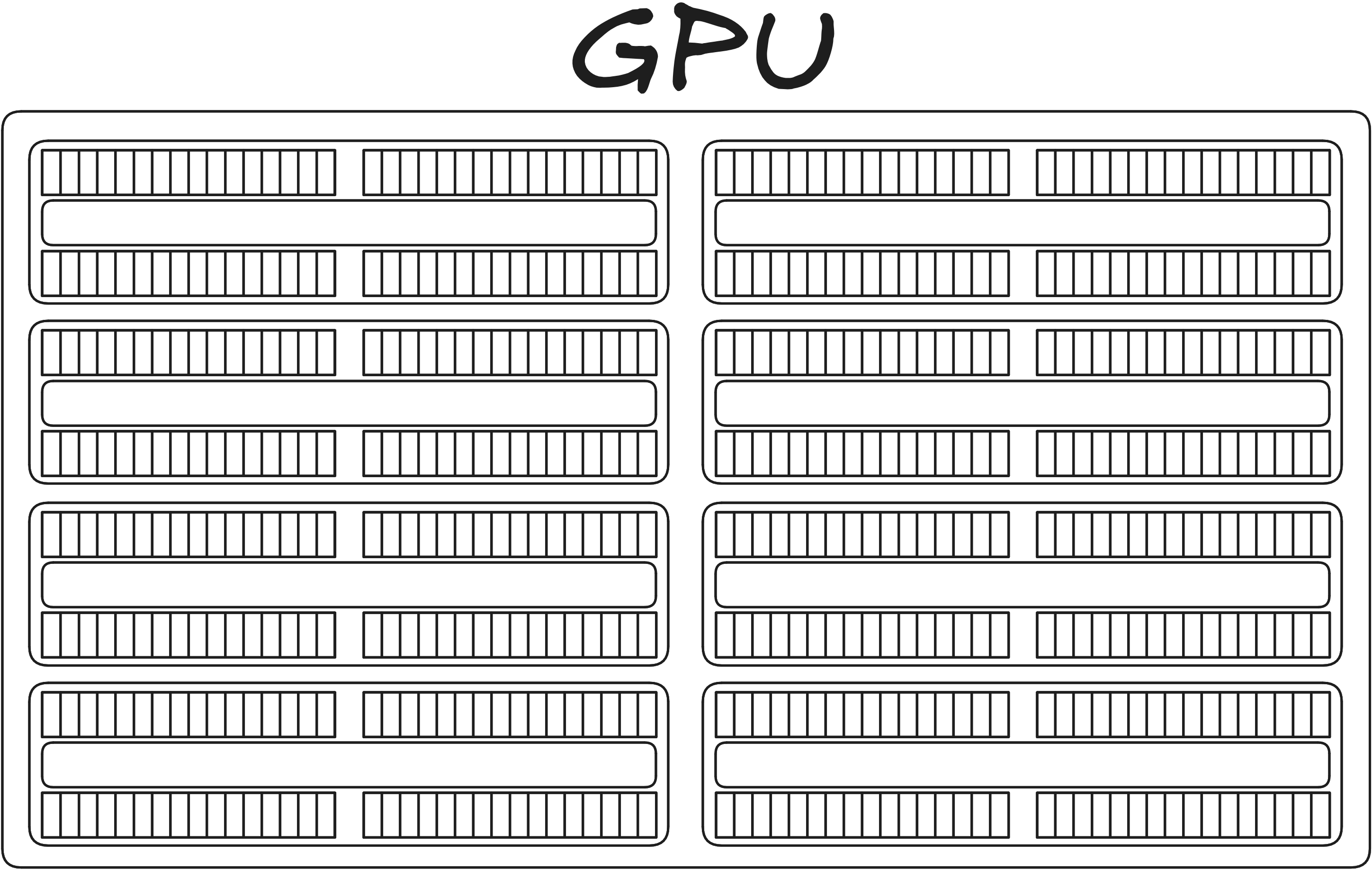 Tens or hundreds of simple processors (this model has 8)
Tens or hundreds of simple processors (this model has 8)
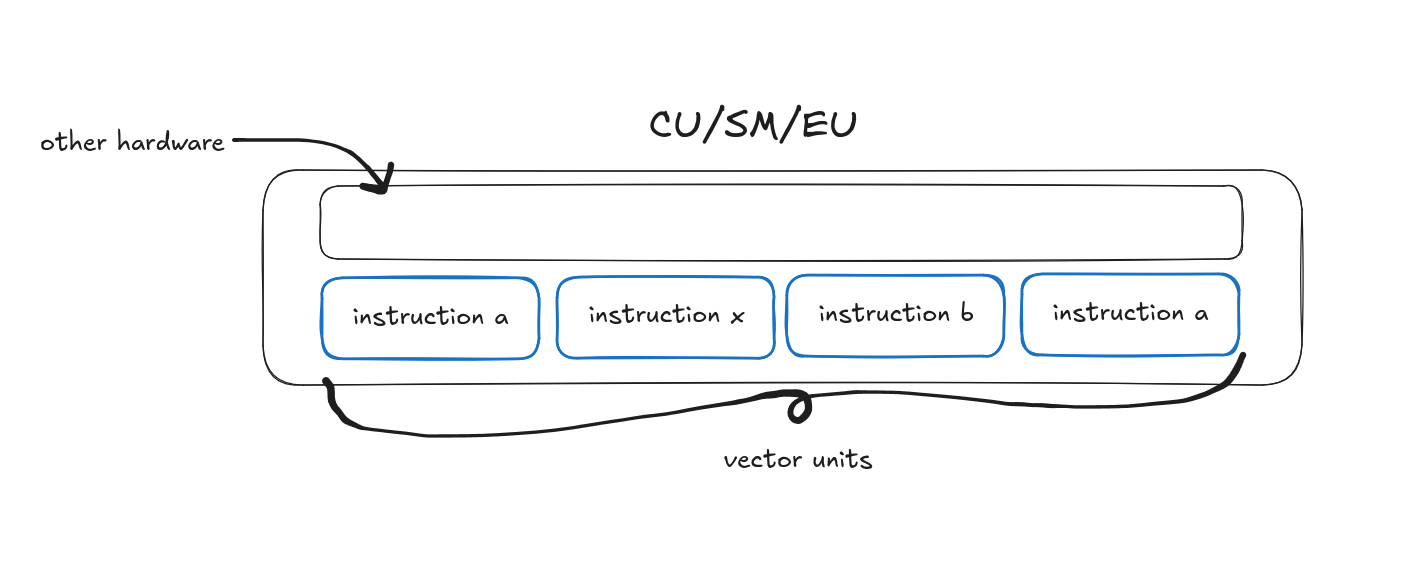
- CU = Compute Unit (AMD)
- SM = Streaming Multiprocessor (Nvidia)
- EU = Execution Unit (Intel)
MI250X

- CUs
- memory
- links to other hardware
Image: LUMI consortium
MI250X, Compute Unit

- 4 “SIMD-units”
- four sets of 16 SIMD lanes and matrix units
- local data share (LDS)
- L1 cache
- scheduler
- other hardware
Image: LUMI consortium
H100

- streaming multiprocessors (SM)
- memory
- links to other hardware
H100, Streaming Multiprocessor

- four SM sub-partitions (SMSP)
- cores for INT32, FP32, FP64
- \(\sim\) SIMD lanes
- L1 Cache (max 128 kB) / Shared memory (max 228 kB)
- other hardware (scheduler, instruction cache etc)
Thread
A single thread is the smallest unit
Block of threads
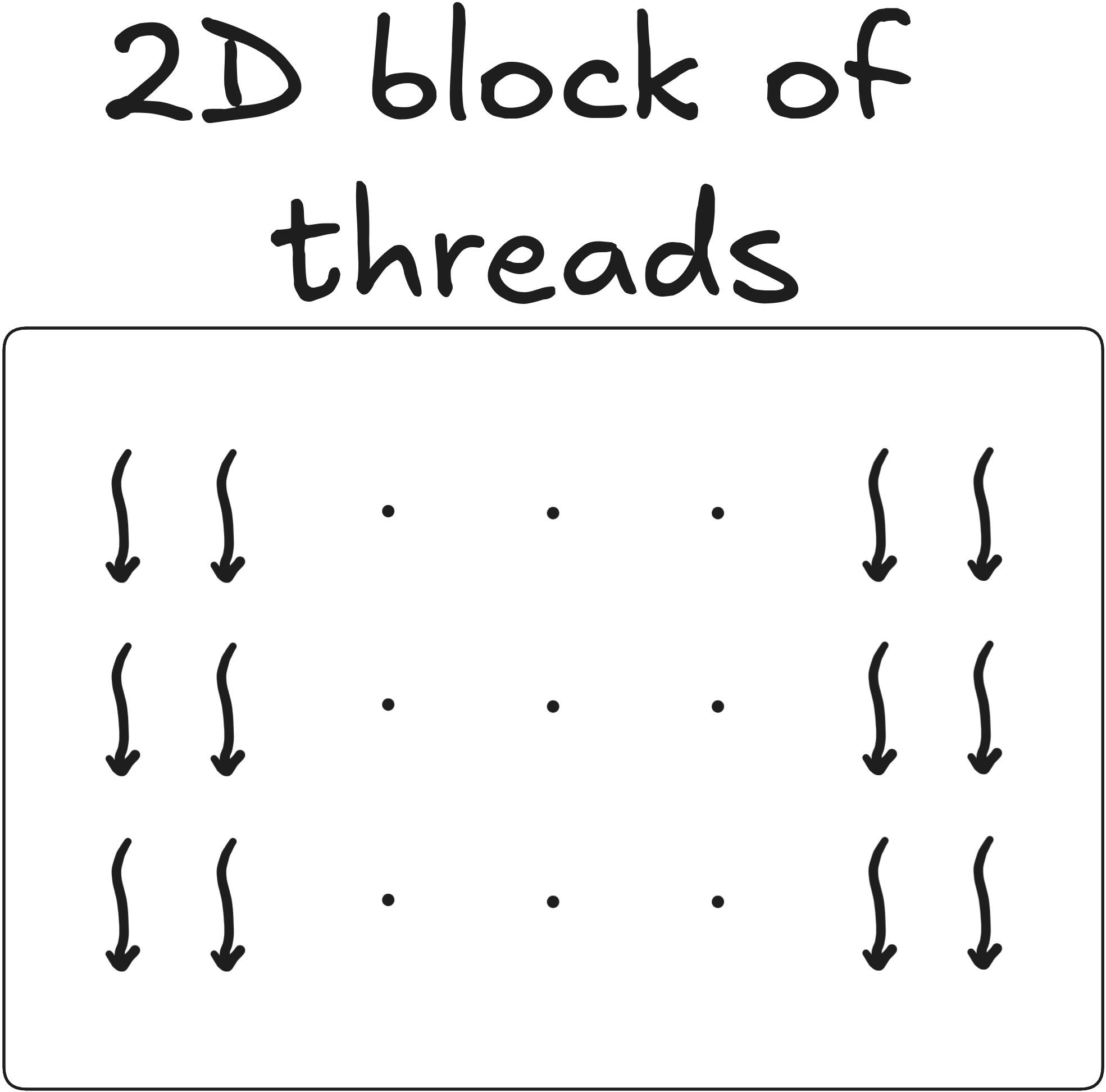
A block of threads can be 1D, 2D or 3D
// This struct is defined elsewhere by the API
struct dim3 {
int32_t x;
int32_t y;
int32_t z;
};
// ------------------------
// In our program we define
// the size of the block:
dim3 block(1024, 1, 1); // 1D
dim3 block(128, 3, 1); // 2D
dim3 block(256, 2, 3); // 3D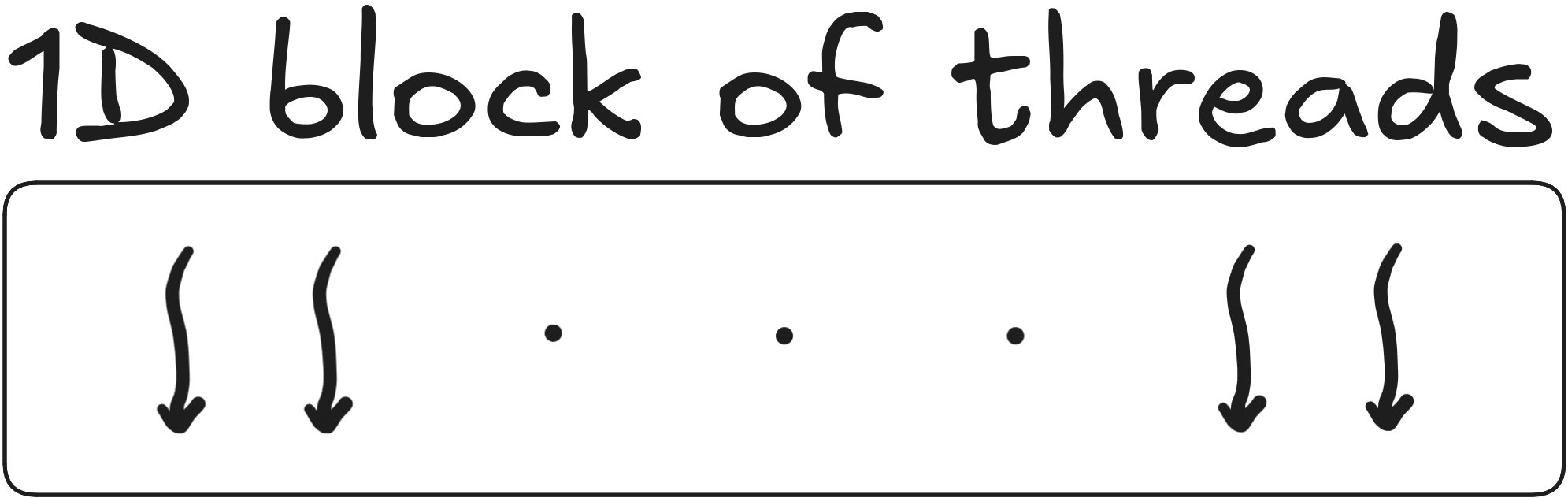
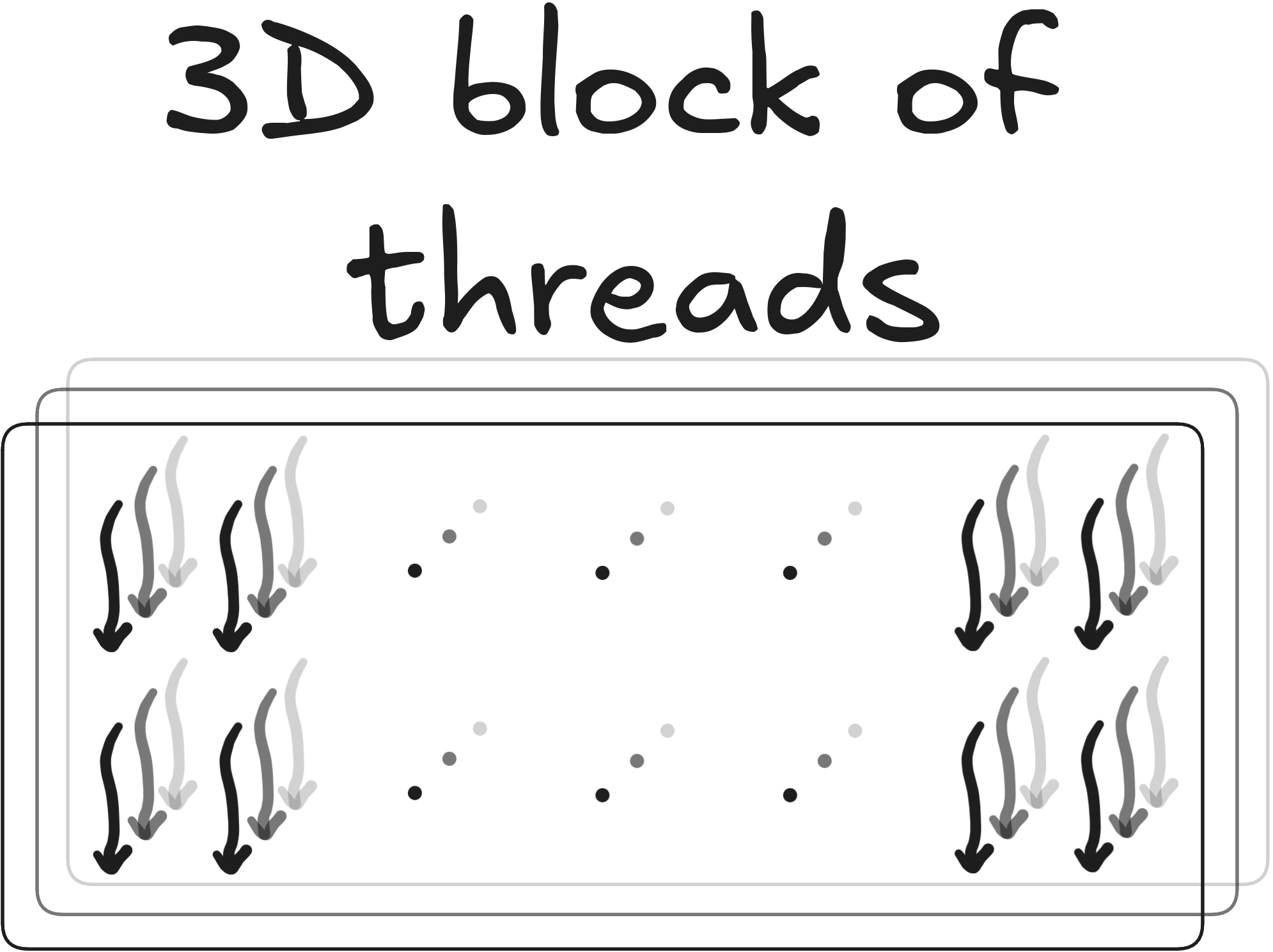
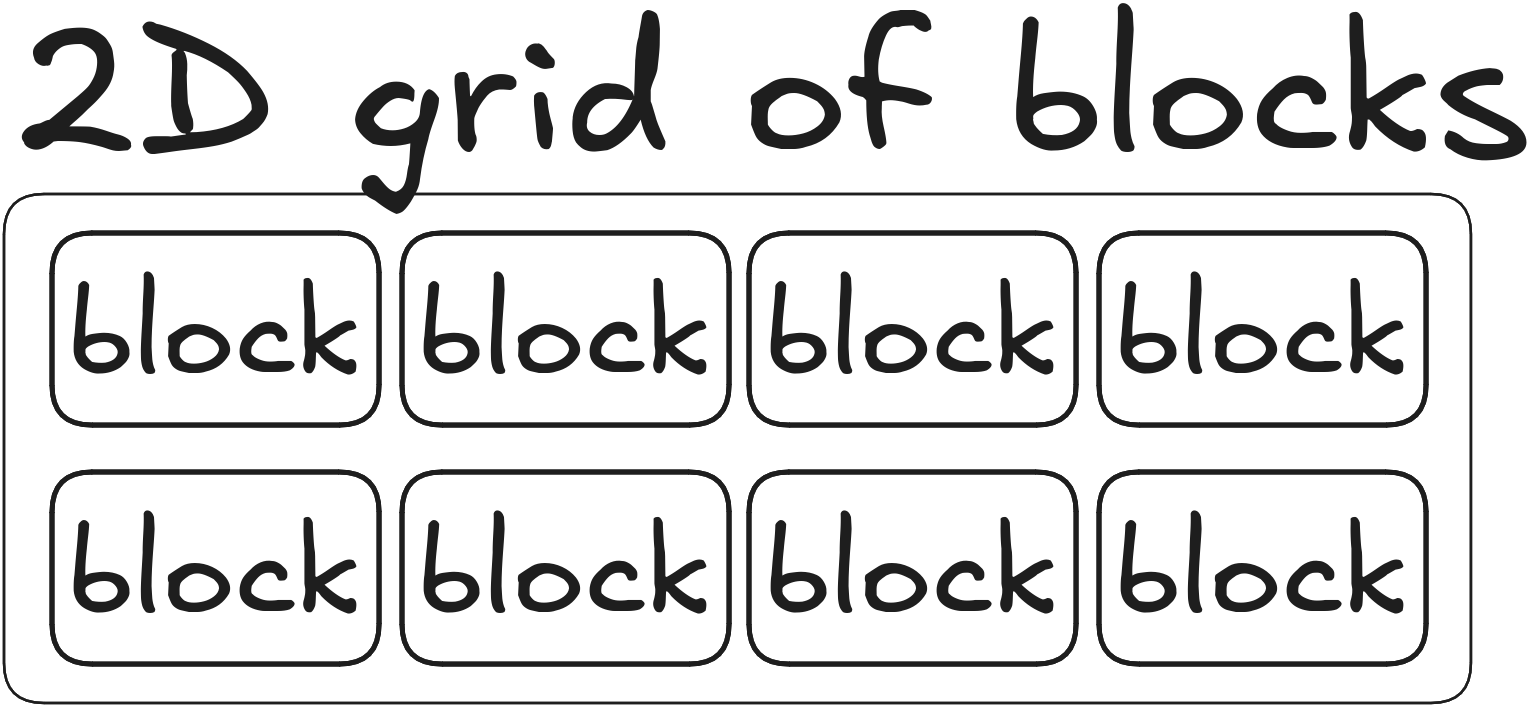
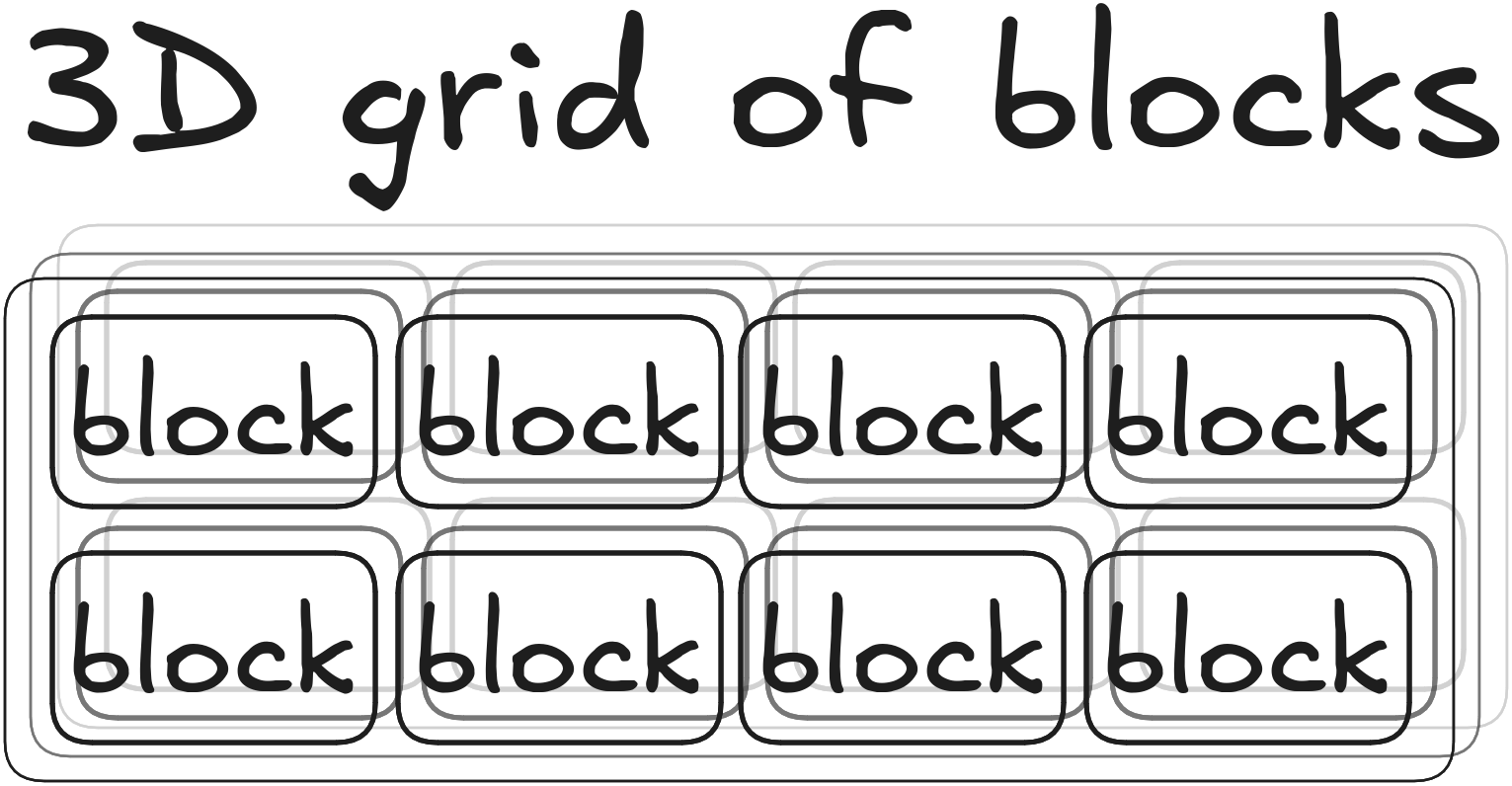
Grid of blocks
A grid of blocks can be 1D, 2D or 3D
// The same struct is used for
// block size and grid size
struct dim3 {
int32_t x;
int32_t y;
int32_t z;
};
// ------------------------
// In our program we define
// the size of the grid:
dim3 grid(4, 1, 1); // 1D
dim3 grid(4, 2, 1); // 2D
dim3 grid(4, 2, 4); // 3D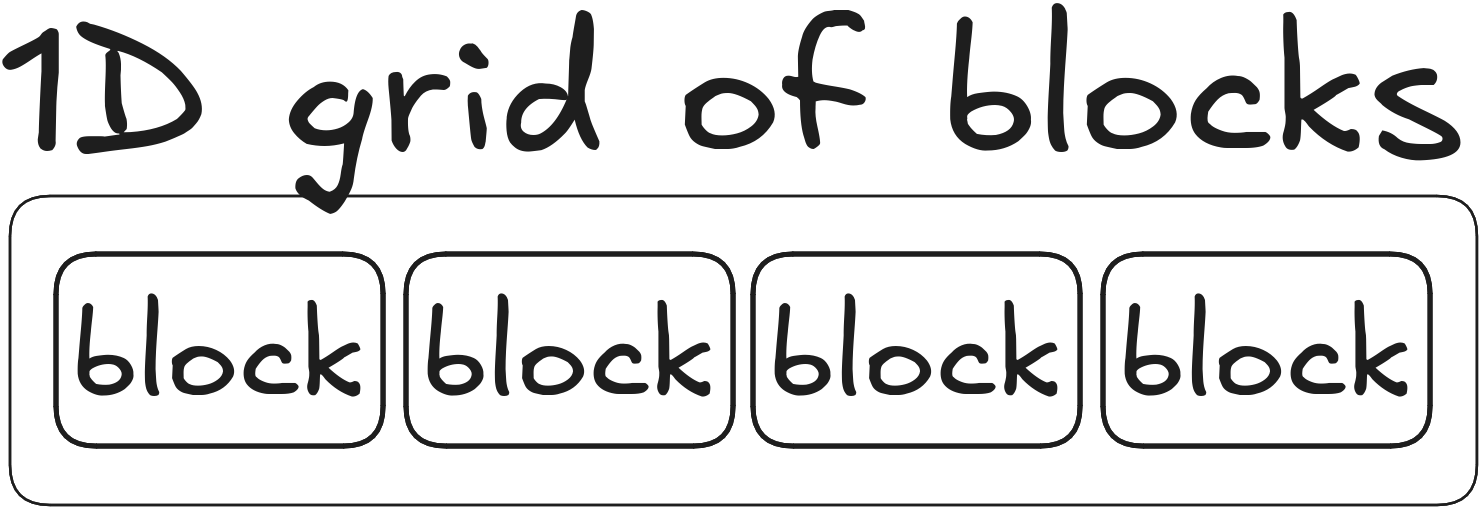
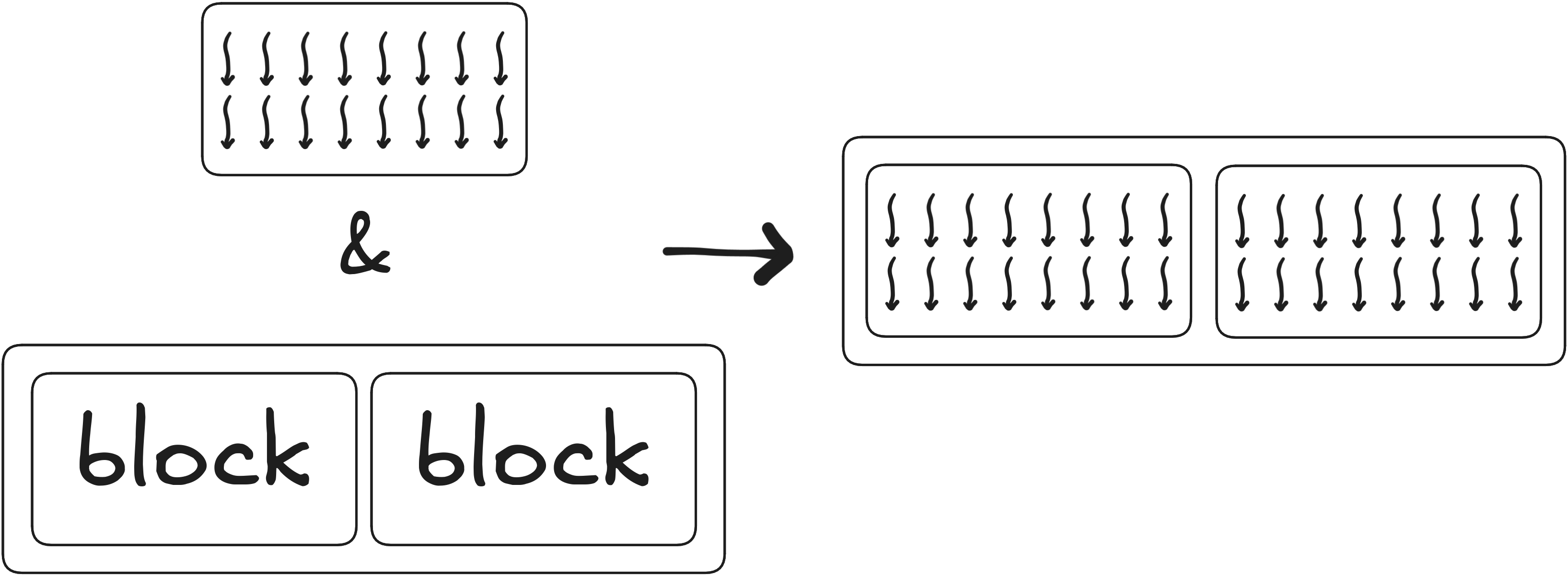
Example grids 1
Example grids 2
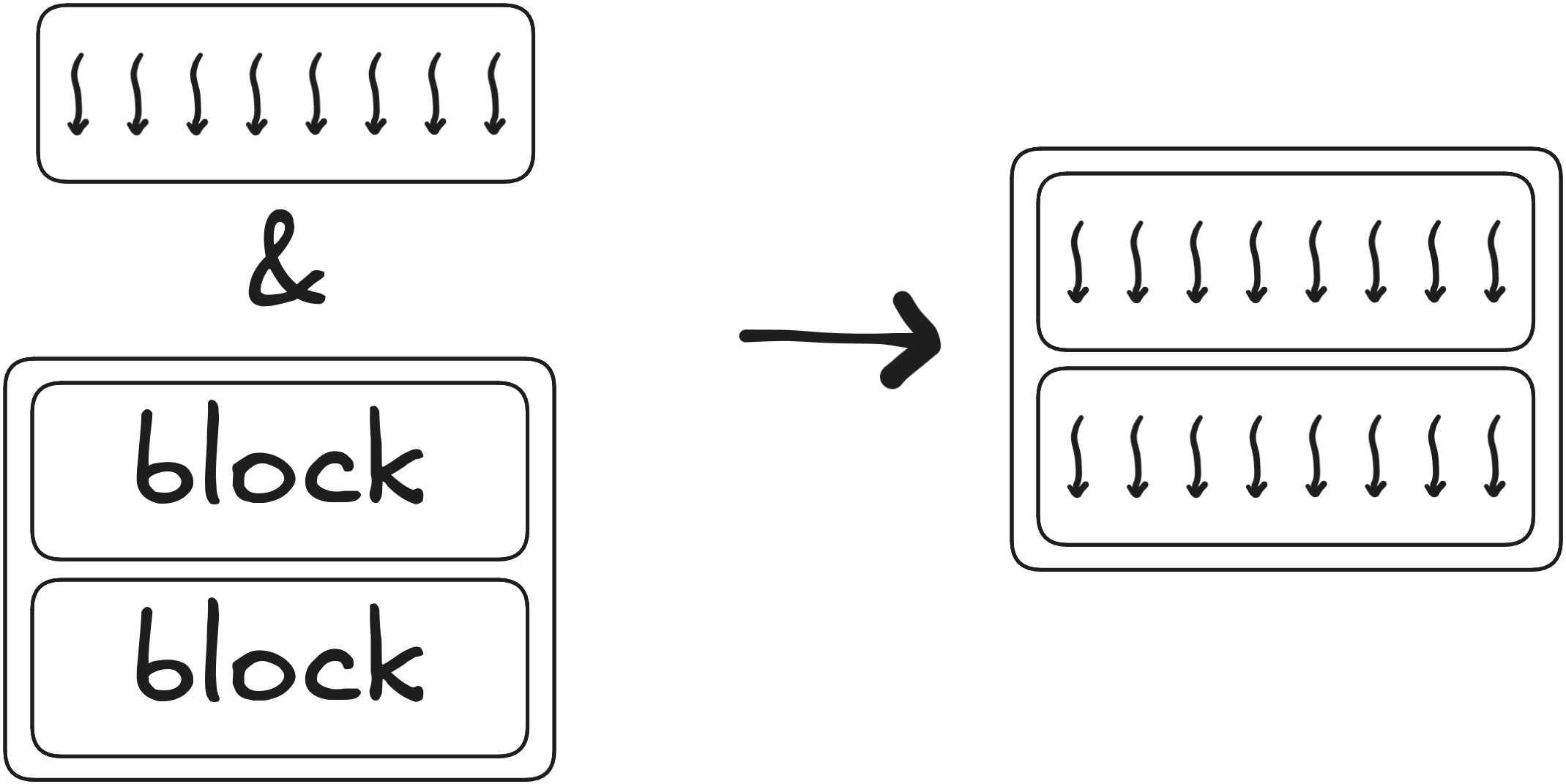
Example grids 3
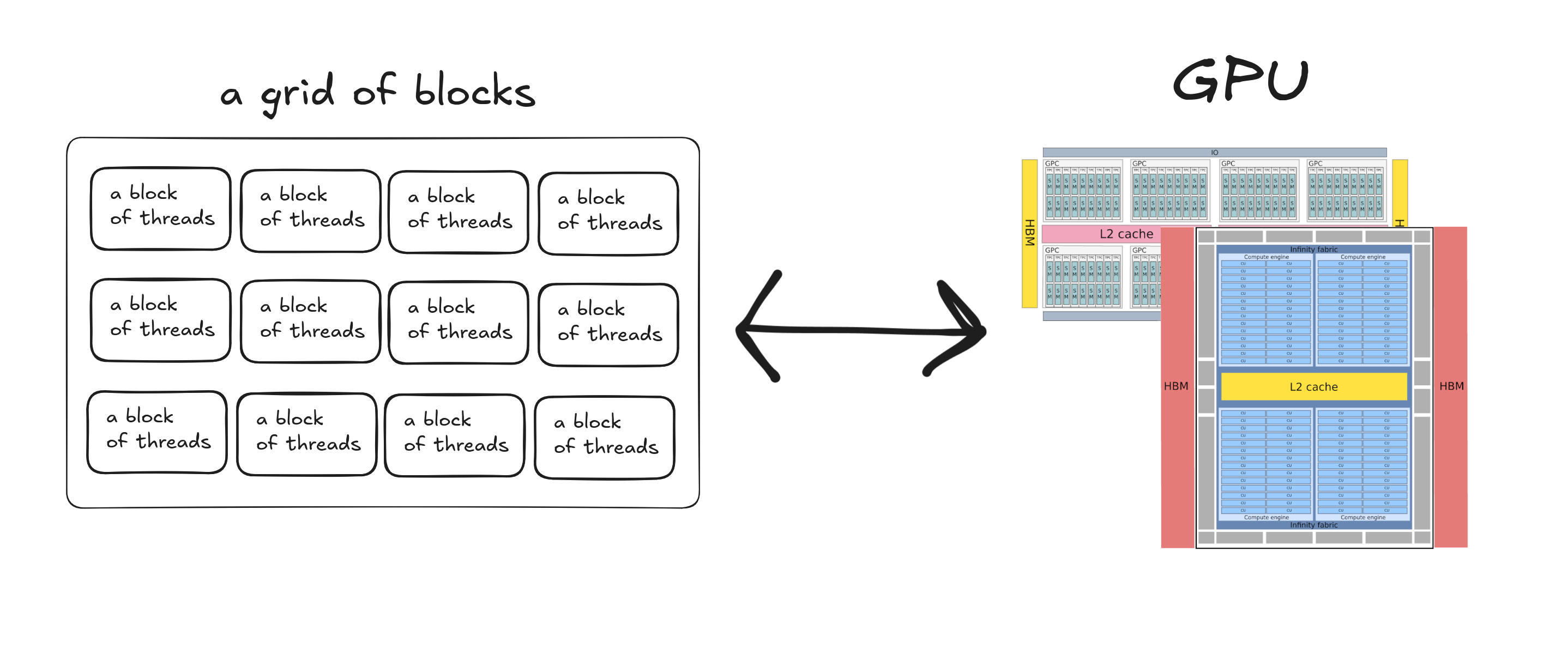
Grid – Device
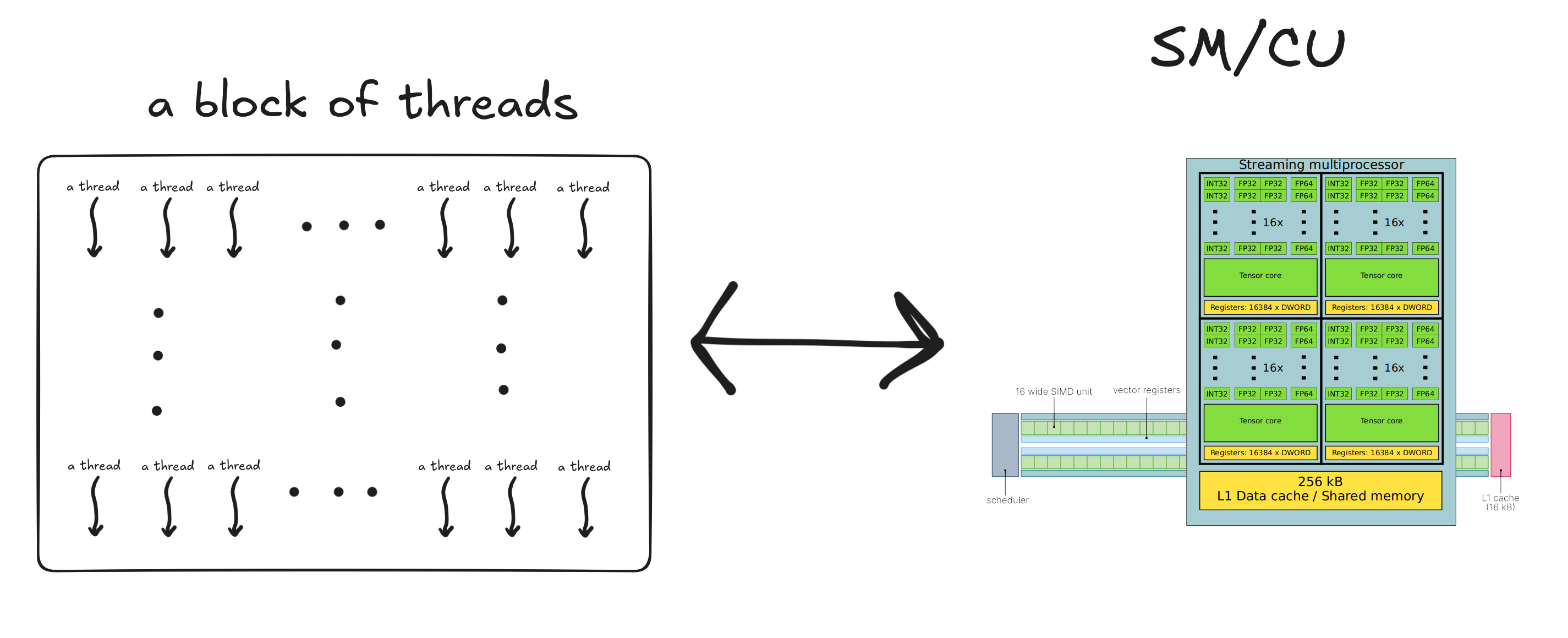
Block – SM/CU
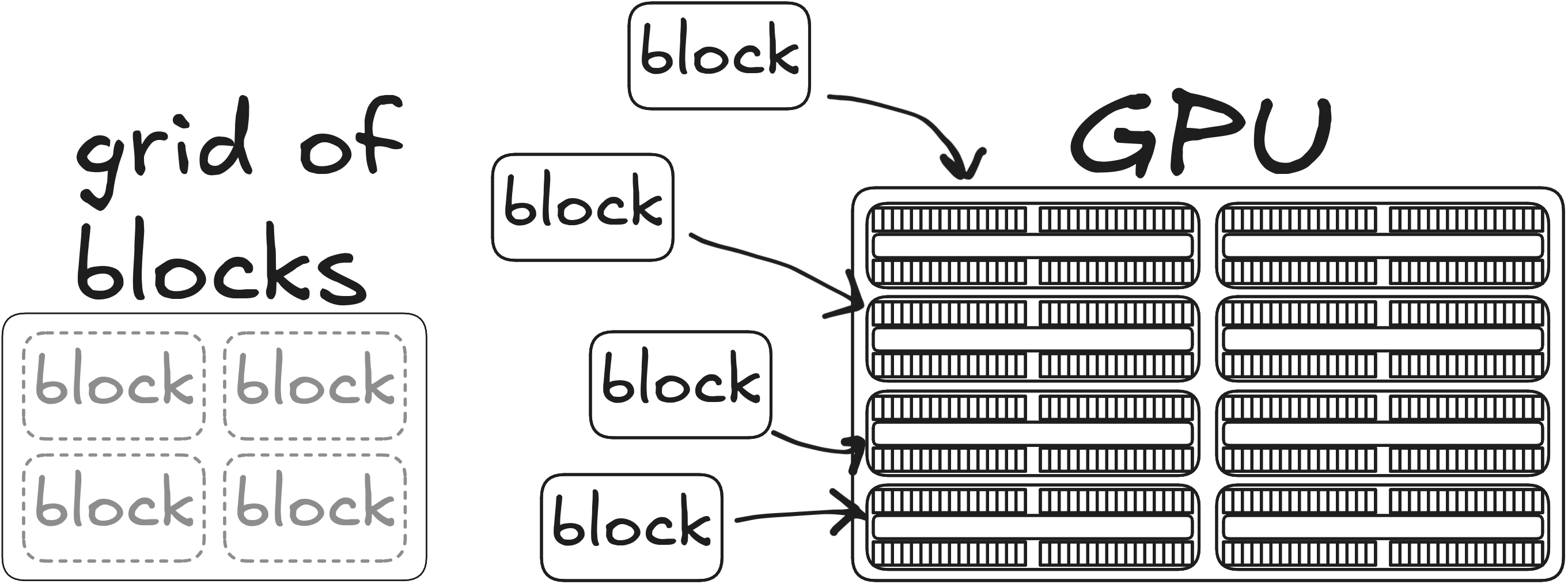
Blocks – SM/CU
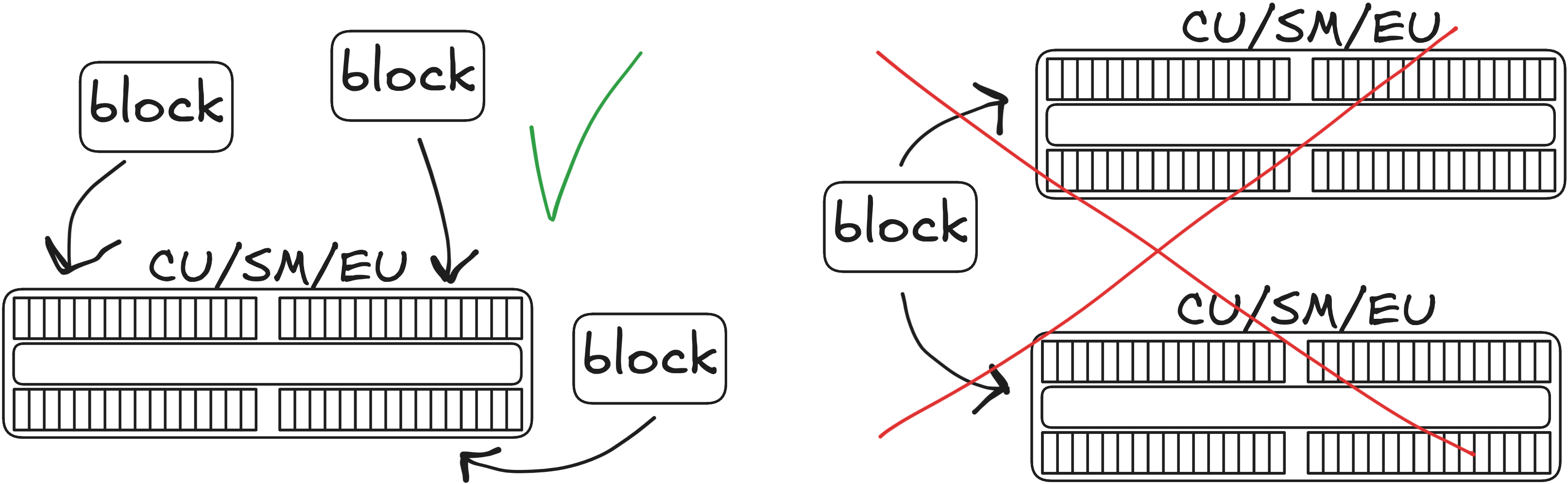
Block – SM/CU
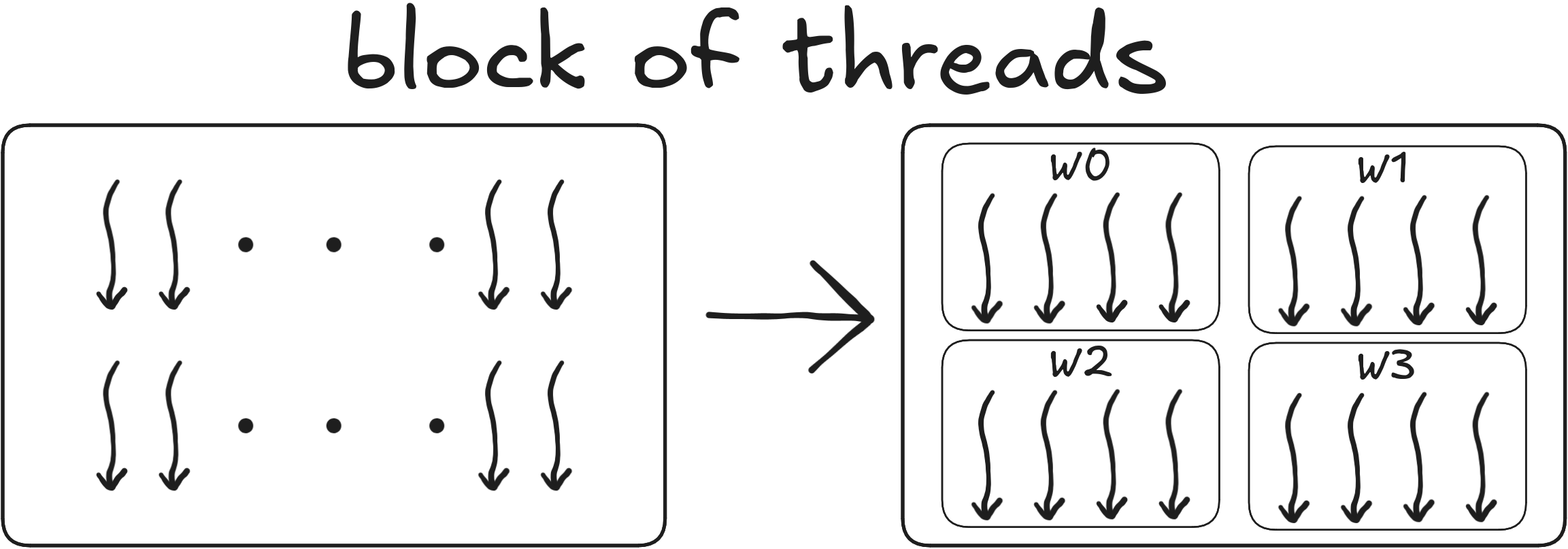
Warps, wavefronts
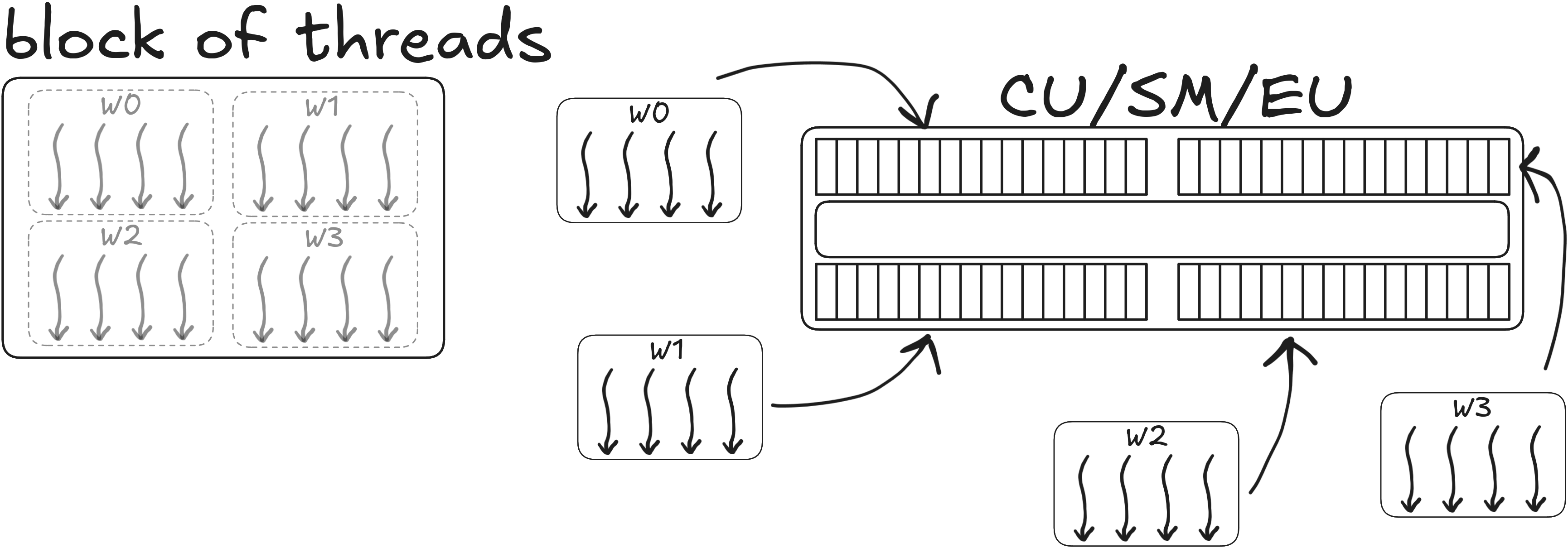
Warp/Wavefront - SMSP/SIMD
Thread - lane
