What is a stream?
- A sequence (queue) of operations that execute in order on the GPU
- Operations in different streams may run concurrently
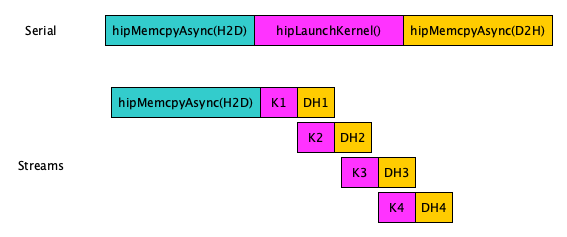
- H-to-D copy runs in a single stream, and the kernel and D-to-H copy are split into 4 streams
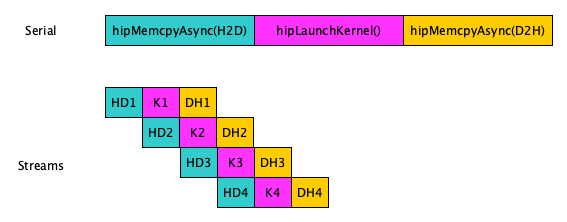
- H-to-D copy, kernel, and D-to-H copy are split into 4 streams
The order of execution in a stream

- Operations are sent to the stream and executed in a FIFO manner
Using multiple streams
- H-to-D copy runs in a single stream, and the kernel and D-to-H copy are split into 4 streams
- H-to-D copy, kernel, and D-to-H copy are split into 4 streams
Stream example
hipStream_t stream[3];
for (int i = 0; i<3; ++i)
hipStreamCreate(&stream[i]);
for (int i = 0; i < 3; ++i) {
hipMemcpyAsync(d_data[i], h_data[i], bytes,
hipMemcpyHostToDevice, stream[i]);
hipkernel<<<grid, block, 0, stream[i]>>>
(d_data[i], i);
hipMemcpyAsync(h_data[i], d_data[i], bytes,
hipMemcpyDeviceToHost, stream[i]);
}
for(int i = 0; i<3; ++i) {
hipStreamSynchronize(stream[i]);
hipStreamDestroy(stream[i]); }
Async memory copy with regular vs page-locked memory

