Memory management and transfers with HIP
GPU programming with HIP
2026-05
CSC Training
Outline
- Memory model and hierarchy
- Memory management strategies
- Page-locked memory
- Asynchronous memory allocation
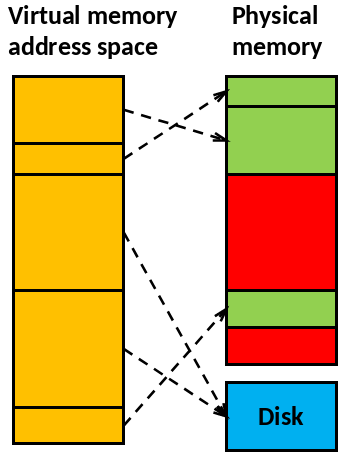
Preface: Virtual Memory addressing
- Modern operating systems utilize virtual memory
- Memory is organized in memory pages
- Memory pages can reside on swap area on the disk
mallocreturns an address in the virtual memory
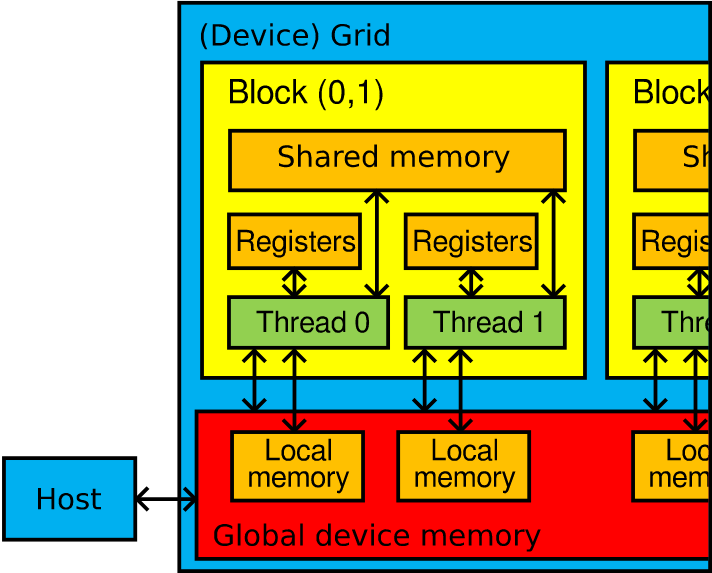
Memory model and hierarchy
- Registers (VGPR, SGPR)
- Compiler assigns automatically
- Shared memory (Local data share, LDS)
- User controlled
- Shared by threads in a block
- Local memory (Scratch)
- Automatically used when registers run out
- Global device memory
- Host memory
Section 1: Memory management strategies
Memory management strategies
Memory management can be Explicit or Implicit.
- Explicit: User manually manages data
movement between host and device. Host memory can be allocated with
GPU-unaware allocators (
malloc/freeetc) - Implicit: The runtime manages data
movement between host and device. Host memory needs to be allocated with
special allocators.
- Managed memory (unified shared memory): Page faults will initiate data movement
Memory management strategies
Explicit memory management
int main() {
int *A, *d_A;
A = (int *) malloc(N*sizeof(int));
hipMalloc((void**)&d_A, N*sizeof(int));
...
/* Copy data to GPU and launch kernel */
hipMemcpy(d_A, A, N*sizeof(int), hipMemcpyHostToDevice);
kernel<<<...>>>(d_A);
hipMemcpy(A, d_A, N*sizeof(int), hipMemcpyDeviceToHost);
hipFree(d_A);
// result is in A
free(A);
}Unified Memory pros & cons
Pros
- Incremental development
- Increased developer productivity
- Especially on large codebases with complex data structures
- Data transfer can be optimized later
- With prefetches and hints
Cons
- Data access in device code is initially slower
⇒ Must be optimized with prefetches and hints - Externalize memory management to library
Unified memory: Prefetching
Unified memory automatically migrates memory pages between CPU and GPU
Without prefetching:
- Memory pages migrate on-demand
- First GPU access may trigger page faults
Programmer can proactively move pages to the GPU before execution
Explicit memory API calls
Allocate device memory
Copy data
Where
kind:hipMemcpyDefault, or
hipMemcpyDeviceToHost,hipMemcpyHostToDevice,hipMemcpyHostToHost,hipMemcpyDeviceToDevice
Deallocate device memory
Unified memory API calls
Also known as Managed memory
Allocate Unified Memory
Deallocate unified memory (same as explicitly managed memory)
Prefetch (asynchronously):
Advise about memory access (more in HIP API Documentation)
Summary about memory management
- Memory management can be Explicit or Implicit
- Unified memory handles memory management between host and device “automatically”
- Any questions about explicit vs. implicit memory management?
Section 2: Efficient memory transfers with pinned host memory
Pageable vs. page-locked memory?
- Modern operating systems utilize virtual memory
- Memory pages can reside on swap area on the disk
- GPU DMA transfers require memory pages to remain resident during the transfer
- Page-locked (“pinned”) memory prevents the OS from swapping these pages out
Page-locked (or pinned) memory
- Normal
mallocallows swapping, page migration and page faults hipHostMallocpage-locks the allocation to a physical memory location- Deallocate with
hipFreeHost()
- Deallocate with
Benefits of page-locking:
- Allow actually asynchronous memory copies
- (possibly) Higher transfer speeds between host and device via direct memory access (DMA)
- Can access host memory from GPU without explicit hipMemcpy (very slow)
Asynchronous memcopies
- Normal
hipMemcpy()calls are blocking (ie, synchronizing)- The execution of host code is blocked until copying is finished
- To overlap copying and program execution, use asynchronous functions
- Such functions have Async suffix, eg,
hipMemcpyAsync()
- Such functions have Async suffix, eg,
- User has to synchronize the program execution
- Concurrency with memory copy and computation requires page-locked host allocations
Async memory copy with regular vs page-locked memory


Explicit memory API calls
Page-locked host memory
Allocate/free page-locked host memory
Memory copy functions are the same as with normally allocated memory
Section 3: Asynchronous memory allocation
Asynchronous allocation: The stream-ordered memory allocator and memory pools
- Benefit of asynchronous memory management: allocate/free memory from/to a pool
| Description | API call |
|---|---|
| Allocate memory from pool. If pool is too small, assign more memory to it. | hipMallocAsync(void** devPtr, size_t size, hipStream_t hStream) |
| Free memory to the pool in the specific stream | hipFreeAsync(void* devPtr, hipStream_t hStream) |
Memory pools - Example
Example 1 - slow
for (int i = 0; i < 100; i++) {
// Allocate memory here (slow)
hipMalloc(&ptr, size);
// Run GPU kernel
kernel<<<..., stream>>>(ptr);
// Deallocate memory here
hipFree(ptr);
}
// Synchronize the default stream (no influence to memory allocations)
hipStreamSynchronize(0); - Allocating and deallocating memory in a loop is slow, and can have a significant impact on the performance
Example 2 - fast
for (int i = 0; i < 100; i++) {
// Obtain unused memory from the current memory pool,
// more memory is allocated for the pool if needed
hipMallocAsync(&ptr, size, stream);
// Run GPU kernel
kernel<<<..., stream>>>(ptr);
// Return memory to the current memory pool
hipFreeAsync(ptr, stream);
}
// Synchronize
hipStreamSynchronize(stream); - Recurring memory allocation and deallocation does not occur anymore, because the memory is obtained from the memory pool
Summary
- Host and device have separate physical memories
- The data copies between CPU and GPU should be minimized
- Explicit or implicit memory management
- Unified Memory: improve productivity and cleaner implementation
- Page-locked host allocation: DMA and kernel access to host memory
- Asynchronous allocation and deallocation: memory pools